
Expresiones regulares
1 Introducción
Las expresiones regulares (re o regex – regular expressions) son una sintaxis, hay quien dice lenguaje, de descripción de texto, para buscar, extraer y manipular patrones de cadena específicos de un texto. Se utilizan ampliamente en el procesamiento del lenguaje natural, las aplicaciones web que requieren la validación de la entrada de cadenas (como la dirección de correo electrónico) y casi la mayoría de los proyectos de Ciencia de datos que implican la minería de texto.
Las expresiones regulares pueden parecer sumamente extrañas, pero una vez que se conocen las reglas de construcción son fáciles de interpretar, aunque hay algunas expresiones regulares que puede terminar siendo tan complicadas que hasta sean difíciles de depurar. En general, la construcción más simple que proporciona el comportamiento requerido es normalmente la más eficiente. Para las expresiones regulares vale la vieja expresión informática KISS (Keep It Simple, Stupid - Hazlo Sencillo, Estúpido) que resume perfectamente que los diseños deben ser cuanto más simples, mejor.
La sintaxis de las expresiones regulares apareció y se estandarizó en el lenguaje Perl, y ahora casi todos los lenguajes de programación soportan PCRE (Perl Compatible Regular Expressions - Expresiones Regulares Compatibles con Perl). En Python, disponemos del módulo estándar re.
El reconocimiento de patrones (Pattern recognition) se emplea para extraer información de objetos en un ámbito determinado. En nuestro caso una expresión regular será el patrón que nos permitirá buscar cadenas específicas en un determinado texto.
Vamos a repasar primero la sintaxis de las expresiones regulares y después pasaremos a ver el módulo re de Python para el manejo de las expresiones y veremos su uso en varios ejemplos.
2 Sintaxis
Las expresiones regulares están formadas por literales y metacaracteres. Los literales son caracteres que requieren una coincidencia exacta, mientras que los metacaracteres son símbolos con un significado especial en la sintaxis de las expresiones regulares. Podemos clasificar los metacaracteres en identificadores y modificadores.
- Los identificadores sirven para reconocer un determinado tipo de caracteres.
- Los modificadores son un conjunto de metacaracteres que añaden más funcionalidad a los identificadores.
Los patrones de las expresiones regulares se comparan con una cadena objetivo de izquierda a derecha.
Una información más amplia está disponible en la organización PCRE.
Una ayuda impagable la encontramos en la página web regular expressions 101, donde podemos validar expresiones regulares en vivo.
2.1 Delimitadores
Cuando usamos expresiones regulares es necesario que el patrón esté encerrado entre símbolos que lo acoten. Un delimitador puede ser cualquier carácter no alfanumérico, que no sea una barra invertida y que no sea un espacio en blanco.
Un carácter muy usado es la barra "/", pero también se pueden utilizar pares de apertura y cierre como paréntesis "()", llaves "{}", corchetes "[]" y corchetes angulares "<>".
/patrón/
Si vamos a trabajar en un entorno donde se emplee mucho un símbolo de los usados como delimitadores, lo más sensato es hacer uso de otro delimitador. Si vamos a analizar texto HTML o XML, donde se usan los corchetes angulares "<>", parece lógico que empleemos cualquier otro juego de entre los delimitadores posibles.
El carácter barra invertida "\" indica que el carácter que le sigue no es un carácter especial, lo que nos permite emplear símbolos delimitadores dentro del patrón sin su significado especial. Supuesto que los paréntesis tuvieran un significado especial, podemos hacer:
/patrón\(texto\)/
En Python no hay ninguna notación especial para delimitar una expresión regular, se representan como cadenas normales. Sin embargo, como la barra invertida es un carácter especial utilizado en las expresiones regulares, pero también se utiliza como carácter de escape en las cadenas, la solución pasa por emplear cadenas sin procesar, cadenas en bruto.
r"patrón"
En la sección siguiente los ejemplos se representan con el formato de delimitadores /patrón/, que aunque no es la forma que empleamos en Python, quizás confunda menos que r"patrón".
2.2 Metacaracteres
Las expresiones regulares codifican acciones sobre las cadenas a analizar, para ello se hace uso de determinados caracteres que dependiendo del contexto tienen un significado especial, los metacaracteres, que no se representan a sí mismos, sino que pueden considerarse como operadores para determinar qué debe coincidir en la consulta.
Hay dos conjuntos diferentes de metacaracteres: aquéllos que son reconocidos en cualquier lugar de un patrón excepto dentro de los corchetes, y aquéllos que son reconocidos dentro de los corchetes.
2.2.1 Metacaracteres fuera de corchetes
Relacionamos en la siguiente tabla aquellos caracteres que son reconocidos en cualquier lugar de un patrón excepto dentro de los corchetes.
Algunos metacaracteres los veremos ampliados más adelante, como los que establecen Cuantificadores o las demominadas Clases carácter.
| Metacaracter | Descripción | Ejemplo |
|---|---|---|
| \ | Carácter de escape general. | |
| ^ | Declaración de inicio de elemento.
Coincide con los caracteres adyacentes al principio de una cadena. Cuando está entre corchetes y seguido de caracteres niega los caracteres que le siguen. | /^Abc/
Empieza por "Abc". |
| $ | Declaración de fin de elemento o antes de la terminación de nueva línea.
Coincide con los caracteres adyacentes al final de una cadena o antes de la terminación de nueva línea o fin línea, en modo multilínea. | /Abc$/
Termina por "Abc". |
| . | Coincide con cualquier carácter (letra, número o símbolo) excepto con el de nueva línea. | |
| [ | Inicio de la definición de la clase carácter. | |
| ] | Fin de la definición de la clase carácter. | |
| | | Inicio de alternativa. | |
| ( | Inicio de subpatrón. | |
| ) | Fin de subpatrón. | |
| ? | Cuantificador 0 ó 1.
Coincide una vez o ninguna con el carácter que le precede. Es lo mismo que poner {0,1} | /ab?/
Una "a" seguida de ninguna o una "b". |
| * | Cuantificador 0 o más.
Coincide ninguna o varias veces con el carácter que le precede. Es lo mismo que poner {0,}. | /ab*/
Una "a" seguida de ninguna, una o varias "b". |
| + | Cuantificador 1 o más.
Coincide una o más veces con el carácter que le precede. Es lo mismo que poner {1,} | /ab+/
Una "a" seguida de una o varias "b". |
| { | Inicio de cuantificador mín/máx. | |
| } | Fin de cuantificador mín/máx. |
2.2.2 Metacaracteres dentro de corchetes
La parte de un patrón que está entre corchetes se denomina clase carácter. En una clase carácter los metacaracteres permitidos son:
| Metacaracter | Descripción |
|---|---|
| \ | Carácter de escape general. |
| ^ | Niega la clase, pero sólo si se trata del primer carácter. |
| - | Define un rango de caracteres. |
2.3 Anclas
Las anclas son metacaracteres que sólo son verdaderas si el punto de coincidencia actual está en el inicio de la cadena objetivo o en el final o inmediatamente antes de un carácter de nueva línea que es el último carácter en la cadena por defecto.
Dentro de una clase carácter, el acento circunflejo "^" tiene un significado totalmente diferente (ver la sección Clases carácter).
| Metacaracter | Descripción | Ejemplo |
|---|---|---|
| ^ | Coincide con los caracteres adyacentes al principio de una cadena | /^Abc/
Empieza por "Abc". No coincide con "xAbc". |
| $ | Coincide con los caracteres adyacentes al final de una cadena | /Abc$/
Termina por "Abc". No coincide con "Abcx". |
2.4 Cuantificadores
Los cuantificadores son metacaracteres que permiten especificar el número de ocurrencias del carácter previo, de un metacaracter o de una subexpresión.
| Cuantificador | Descripción | Ejemplo |
|---|---|---|
| * | Cero o más veces.
Coincide ninguna o varias veces con el carácter que le precede. Equivale a {0,}. | /ab*c/
Una "a" seguida de cero o más "b", seguido de una "c". |
| + | Una o más veces.
Coincide una o más veces con el carácter que le precede. Equivale a {1,}. | /ab+c/
Una "a" seguida de una o más "b", seguido de una "c". |
| ? | Cero o una vez.
Coincide una vez o ninguna con el carácter que le precede. Equivale a {0,1}. | /ab?c/
Una "a" seguida de cero o una "b", seguido de una "c". |
| {n} | Exactamente n veces. | /ab{3}c/
Una "a" seguida de tres "b", seguido de una "c". |
| {n,} | Por lo menos n veces. | /ab{3,}c/
Una "a" seguida de por lo menos tres "b", seguido de una "c". |
| {n,m} | Por lo menos n pero no más de m veces. | /ab{3,4}c/
Una "a" seguida de por lo menos tres "b" y no más de cuatro, seguido de una "c". |
| *? | Cero o más veces.
Equivale a {0,}?. | |
| +? | Una o más veces.
Equivale a {1,}?. | |
| ?? | Cero o una vez.
Equivale a {0,1}?. |
2.5 Clases carácter
Una clase carácter contiene caracteres específicos y rangos de valores encerrados entre corchetes.
El carácter guión "-" se usa para especificar un rango de caracteres en una clase carácter. Los rangos operan según la secuencia ASCII, así, si queremos letras minúsculas y mayúsculas debemos especificar ambas, ya que no están seguidas en la secuencia ASCII: [a-zA-Z].
| Grupo | Descripción | Ejemplo |
|---|---|---|
| [patrón] | Coincide con los caracteres entre corchetes en cualquier orden y punto de la cadena. | /[abc]/
Cualquier carácter "a", "b" o "c". /[a-z]/ Cualquier carácter alfabético en minúscula. /[a-zA-Z]/ Cualquier carácter alfabético. |
| [^patrón] | Coincide con los caracteres que no estén entre corchetes en cualquier orden y punto de la cadena. | /[^abc]/
Cualquier carácter alfabético que no sea "a", "b" o "c". /[^123]/ Cualquier número excepto "1", "2" o "3". |
| - | Concuerda con cualquier carácter en el intervalo de caracteres definido entre los corchetes, en cualquier punto de la cadena.
Si se quiere buscar un guión debe colocarse al principio o al final de la clase. | /[0-9]/
Cualquier número del 0 al 9. /[a-z-]/ Cualquier letra minúscula o el guión. |
2.6 Clases carácter predefinidas
Las clases carácter predefinidas representan un conjunto de caracteres, lo que permite construir expresiones regulares con patrones más compactos.
| Clase | Descripción | Grupo |
|---|---|---|
| \d | Dígito. | [0-9] |
| \D | Ningún dígito. | [^0-9] |
| \w | Caracteres alfanuméricos más el carácter "_". | [A-Za-z0-9_] |
| \W | Ningún carácter alfanumérico ni "_". | [^A-Za-z0-9_] |
| \s | Espacio en blanco. | [ \t\n\r\f\v] |
| \S | Ningún espacio en blanco. | [^ \t\n\r\f\v] |
| \b | Coincide con la cadena vacía, pero sólo al principio o al final de una palabra. | |
| \B | Coincide con la cadena vacía, pero NO al principio o al final de una palabra. | |
| \A | Caracteres al principio de la cadena. | |
| \Z | Caracteres al final de la cadena. | |
| \número | Contenido del grupo del número indicado. Es un número positivo entre 1 y 99. |
2.7 Grupos
Los grupos son un patrón delimitado por paréntesis. Al agrupar una parte de una expresión regular podemos aplicar los operadores al grupo completo en lugar de a un solo carácter.
Pero los paréntesis no sólo agrupan subexpresiones, sino que también crean referencias. La subexpresión entre paréntesis se almacena en una referencia que podemos reutilizar en otra parte de la expresión regular o una vez que hayamos ejecutado la expresión.
| Grupo | Descripción | Ejemplo |
|---|---|---|
| (patrón) | Coincide con los caracteres entre paréntesis en el mismo orden, en cualquier punto de la cadena.
Se guarda cada paréntesis en una variable numerada entre el 1 y el 99; siempre en incrementos desde 1 por cada par de paréntesis en el patrón. La variable 0 corresponde con el texto que ha encontrado el patrón. | /(ABC.)(ABC.)/
Con "ABC123ABC456" guarda: 0 - "ABC123ABC456" 1 - "ABC123" 2 - "ABC456" |
| (?:patrón) | Encuentra lo que coincide con el patrón pero no lo guarda. | /(?:ABC.)(ABC.)/
Con "ABC123ABC456" guarda: 0 - "ABC123ABC456" 1 - "ABC456" |
| (?P<nombre>patrón) | Encuentra lo que coincide con el patrón y lo guarda mediante su posición numérica normal y también mediante su nombre. |
2.8 Operadores lógicos
En ocasiones necesitamos elegir entre varias expresiones regulares, para lo que disponemos del operador lógico OR, representado por la barra vertical "|".
| Operador | Descripción |
|---|---|
| patrón1|patrón2 | patrón1 o patrón2. |
| patrón1(?=patron2) | Encuentra patrón1 solo si le sigue patrón2. |
| patrón1(?!patrón2) | Encuentra patrón1 solo si no le sigue patrón2. |
| (?<=patrón2)patrón1 | Encuentra patrón1 solo si le antecede patrón2. |
| (?<!patrón2)patrón1 | Encuentra patrón1 solo si no le antecede patrón2. |
2.9 Modificadores
Nos permiten dar mayor información a la expresión. Siempre van al final y fuera del delimitador.
| Flag | Descripción | Ejemplo |
|---|---|---|
| i | No distingue entre mayúsculas y minúsculas. | /abc/i
No distinguir entre "abc", "ABC" o "Abc". |
| g | Busqueda global de todas las coincidencias, no sólo la primera. | /abc/g"
"abcxyzabc". |
| m | Encuentra los saltos de línea "\n", para separar cada línea de un texto. | /^A/m |
3 Módulo re
El módulo re de Python, que forma parte de la biblioteca estándar, proporciona el tratamiento de expresiones regulares. Para usarlo debemos empezar importando el módulo.
import re
3.1 Funciones
El módulo re dispone de las funciones.
| Función | Descripción |
|---|---|
| re.compile(pattern, flags=0) | Compila un patrón de expresión regular en un objeto regex, que puede ser usado para las coincidencias usando match(), search() y otros métodos |
| re.escape(pattern) | Caracteres de escape especiales en el patrón pattern.
Cuando se quiere hacer coincidir una cadena literal arbitraria que puede tener metacaracteres de expresión regular en ella. |
| re.findall(pattern, string, flags=0) | Devuelve una lista con todas las coincidencias no superpuestas del patrón pattern en la cadena string, como una lista de cadenas o tuplas.
La cadena se escanea de izquierda a derecha y las coincidencias se devuelven en el orden en que se encuentran. Las coincidencias vacías se incluyen en el resultado. El resultado depende del número de grupos detectados en el patrón. Si no hay grupos, devuelve una lista de cadenas que coincidan con el patrón completo. Si existe exactamente un grupo, retorna una lista de cadenas que coincidan con ese grupo. Si hay varios grupos presentes, retorna una lista de tuplas de cadenas que coinciden con los grupos. Los grupos que no son detectados no afectan la forma del resultado. |
| re.finditer(pattern, string, flags=0) | Devuelve un iterador que produce objetos de coincidencia sobre todas las coincidencias no superpuestas para el patrón pattern en la cadena string. La cadena se examina de izquierda a derecha, y las coincidencias se devuelven en el orden en que se encuentran. Las coincidencias vacías se incluyen en el resultado. |
| re.fullmatch(pattern, string, flags=0) | Comprueba si toda la cadena string coincide con el patrón pattern de la expresión regular.
Devuelve un objeto match si hay coincidencia. Devuelve None si la cadena no coincide con el patrón. |
| re.match(pattern, string, flags=0) | Busca si cero o más caracteres al principio de la cadena string coinciden con el patrón pattern de la expresión regular. Devuelve un objeto match si hay una coincidencia.
|
| re.purge() | Limpia la caché de expresión regular. |
| re.search(pattern, string, flags=0) | Examina la cadena string buscando el primer lugar donde el patrón pattern de la expresión regular produce una coincidencia.
Devuelve un objeto match si hay una coincidencia. Devuelve None si no hay coincidencia con el patrón. |
| re.split(pattern, string, maxsplit=0, flags=0) | Devuelve una lista con las ocurrencias en la que la cadena string se ha dividido en cada coincidencia del patrón pattern.
Si se utilizan paréntesis de captura en el patrón, el texto de todos los grupos en el patrón también se devuelven como parte de la lista resultante. Si el argumento maxsplit es distinto de cero, como mucho se producen el número de divisiones indicado, y el resto de la cadena se devuelve como un elemento final de la lista. |
| re.sub(pattern, repl, string, count=0, flags=0) | Devuelve la cadena obtenida reemplazando las ocurrencias no superpuestas del patrón pattern en la cadena string sustituidas por la cadena de reemplazo repl.
Si el patrón no se encuentra, se devuelve la cadena sin cambios. El argumento repl puede ser una cadena o una función; si es una cadena, cualquier barra inversa de escape se procesa. Las referencias inversas, se reemplazan por la subcadena que corresponde al grupo indicado del patrón. Si repl es una función, se llama para cada ocurrencia no superpuesta del patrón. La función toma un solo argumento objeto match, y retorna la cadena de sustitución. El argumento opcional count es el número máximo de ocurrencias de patrones a ser reemplazados; count debe ser un número entero no negativo. Si se omite o es cero, se reemplazan todas las ocurrencias. Las coincidencias vacías del patrón se reemplazan sólo cuando no están adyacentes a una coincidencia vacía anterior |
| re.subn(pattern, repl, string, count=0, flags=0) | Similar a sub() excepto que devuelve una tupla que contiene la nueva cadena y el número de sustituciones realizadas. |
3.1.1 Objeto match
Las funciones search(), match() y fullmatch() devuelven un objeto match que proporciona información sobre la búsqueda y su resultado. Los siguientes métodos nos permiten acceder a la información contenida en el objeto match.
| Método | Descripción |
|---|---|
| end(n) | Devuelve la posición final de la coincidencia. |
| group(n) | Devuelve la cadena coincidente. |
| groupdict() | Devuelve un diccionario con todos los grupos coincidentes. |
| groups() | Devuelve una tupla con todos los grupos coincidentes. |
| span(n) | Devuelve una tupla (start, end) que especifica las posiciones de la coincidencia en la cadena a analizar. |
| start(n) | Devuelve la posición inicial de la coincidencia. |
El parámetro n referencia un grupo. Puede ser:
- Un número positivo entre 1 y 99.
- Una cadena que identifica el nombre del grupo.
3.2 Indicadores
En algunas funciones podemos modificar el comportamiento de la expresión regular haciendo uso de indicadores para el parámetro flags.
Los valores pueden ser cualquiera de las siguientes variables, combinadas usando el operador OR ( | ).
| Indicador | Descripción |
|---|---|
| re.ASCII re.A | Hace que \w, \W, \b, \B, \d, \D, \s y \S realicen una coincidencia ASCII en lugar de una concordancia Unicode. Esto sólo tiene sentido para los patrones de Unicode, y se ignora para los patrones de bytes. |
| re.DEBUG | Muestra información de depuración sobre la expresión compilada. |
| re.IGNORECASE re.I | Realiza una coincidencia insensible a las mayúsculas y minúsculas. |
| re.LOCALE re.L | Hace que las coincidencias \w, \W, \b, \B y las coincidencias insensibles a mayúsculas y minúsculas dependan de la configuración regional vigente. Este indicador sólo puede ser usado con patrones de bytes.
Sólo la configuración regional durante la coincidencia afecta al resultado obtenido. |
| re.MULTILINE re.M | Cuando se especifica, el patrón de caracteres "^" coincide al principio de la cadena y al principio de cada línea inmediatamente después de cada nueva línea; y el patrón de caracteres "$" coincide al final de la cadena y al final de cada línea inmediatamente antes de cada nueva línea. |
| re.DOTALL re.S | Hace que el carácter especial punto "." coincida con cualquier carácter, incluyendo una nueva línea. Sin este indicador, "." coincidirá con cualquier cosa, excepto con una nueva línea. |
| re.VERBOSE re.X | Permite escribir expresiones regulares en cadena multilínea y añadir comentarios. Se ignorarán los saltos de línea en la expresión regular. Tiene sentido cuando la expresión regular está definida en un cadena multilínea. |
4 Empleo de expresiones regulares
Escribir expresiones regulares no es algo trivial, sobre todo si el texto a analizar es complejo. Aquí no vamos a dar un curso de especialización sobre cómo construir expresiones regulares, tan solo nos limitaremos a ver cómo se pueden usar, empleando las funciones que hemos expuesto anteriormente. Trataremos de cubrir el máximo de objetos y patrones, explicando la construcción de las expresiones que usemos.
4.1 Comprobación/validación
Vamos a validar una hora con el formato estándar
hh:mm:ss
- hh - La hora admite valores de 00 a 23.
- mm - Los minutos admiten valores de 00 a 59.
- ss - Los segundos admiten valores de 00 a 59.
Para la hora vamos a emplear dos patrones, uno que nos validará los posibles valores de 00 a 19, de la forma: un 0 o un 1 seguido de un dígito. Y otro que cubre los valores de 20 a 23, de la forma: un 2 seguido de un número de 0 a 3. Unidos ambos con un operador OR ( | ).
Para minutos y segundos nos vale con un patrón que nos valide: un primer dígito de 0 a 5 seguido de un dígito de 0 a 9.
Que puesto en forma de una expresión regular sería:
([0-1]\d|2[0-3]):[0-5]\d:[0-5]\d
Cuya descomposición la tenemos en el gráfico siguiente.
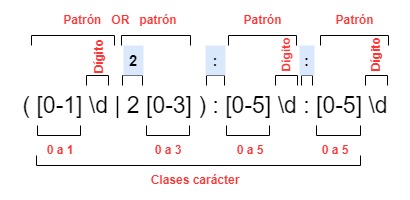
Descomposición de la expresión regular
La expresión que nos valida los dos dígitos de la hora debemos encerrarla entre paréntesis, no porque queramos definir un grupo, sino porque con el operador OR, sin los paréntesis, el analizador entendería el patrón como:
[0-1]\d OR 2[0-3]:[0-5]\d:[0-5]\d
Un patrón que buscaría un dígito de 0 a 1 seguido de un dígito, o un patrón que buscaría un 2 seguido de un dígito de 0 a 3, dos puntos (:), etc.
Construimos un segundo patrón mas compacto, que nos permitirá validar incluso horas cortas, solo horas y minutos. Como el patrón de minutos y segundos es idéntico, utilizaremos solo uno, con un cuantificador que establece un mínimo de una ocurrencia y un máximo de dos.
([0-1]\d|2[0-3])(:[0-5]\d){1,2}
La descomposición de la nueva expresión la tenemos en el gráfico siguiente.
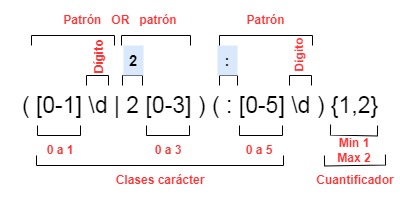
Descomposición de la expresión más compacta
Preparamos un guión que hará uso de ambas expresiones, la larga y la corta.
import re
# hora
# dos patrones con un operador OR (|)
# primer patrón [0-1]\d
# un dígito de 0 a 1 seguido de un dígito: 00 a 19
# segundo patrón 2[0-3]
# un 2 seguido de un dígito de 0 a 3: 20 a 23
#
# minutos y segundos
# patrón [0-5]\d
# un dígito de 0 a 5 seguido de un dígito: 00 hasta 59
exp = r'([0-1]\d|2[0-3]):[0-5]\d:[0-5]\d'
hora_ok = '03:28:59'
res = re.fullmatch(exp, hora_ok)
if res:
print('hora correcta')
print(res.group())
hora_nok = '24:60:59'
res = re.fullmatch(exp, hora_nok)
if res:
print(res.group())
else:
print('\nhora errónea')
# expresión compacta
exp = r'([0-1]\d|2[0-3])(:[0-5]\d){1,2}'
res = re.fullmatch(exp, hora_ok)
if res:
print('\nhora correcta')
print(res.group())
hora_minutos = '03:28'
res = re.fullmatch(exp, hora_minutos)
if res:
print('\nhora corta correcta')
print(res.group())
La ejecución del guión nos ofrece el resultado:
hora correcta 03:28:59 hora errónea hora correcta 03:28:59 hora corta correcta 03:28
4.2 Validar dirección de email
Siempre que se escribe sobre expresiones regulares parece que hay que validar una dirección de correo electrónico. No vamos a ser menos.
Una dirección de correo, según el RFC 5322 está formada por:
<parte_local>@<dominio>
La parte local de la dirección de correo electrónico puede ir sin comillas o entre comillas. La longitud total máxima de la parte local de una dirección de correo electrónico es de 64 octetos.
Si no está entre comillas, puede utilizar cualquiera de los caracteres ASCII:
- letras de la A a la Z y de la a a la z
- dígitos del 0 al 9
- caracteres imprimibles !#$%&'*+-/=?^_`{|}~
- punto ., siempre que no sea el primer o el último carácter y siempre también que no aparezca consecutivamente
La parte del nombre de dominio de una dirección de correo electrónico debe coincidir con los requisitos de un nombre de host, una lista de etiquetas DNS separadas por puntos, cada una de las cuales debe tener una longitud máxima de 63 caracteres y estar formada por:
- letras de la A a la Z y de la a a la z
- dígitos del 0 al 9, siempre que los nombres de dominio de primer nivel no sean totalmente numéricos
- guión -, siempre que no sea el primer o el último carácter
Vamos a simplificar, no hay que ser tan ambicioso para un ejemplo. Supondremos direcciones de correo con el formato:
<identificación>@<host>.<dominio>
Donde:
- identificación es una cadena alfanumérica que incluye "_", "-" y "."
- host es una cadena alfanumérica
- dominio es una cadena alfabética de 3 caracteres
La primera aproximación que hemos realizado es:
([A-Za-z0-9]+[\.-_]?)*[A-Za-z0-9]+@[A-Za-z0-9.-]+\.([A-Za-z]{2,3})?
Que podemos leer de la forma:
Con ningún o un carácter punto (.), guión (-) o guion bajo (_): [\.-_]?
Ambos cero o más veces: ([A-Za-z0-9]+[\.-_]?)*
Seguidos de una cadena alfanumérica, mínimo una vez: [A-Za-z0-9]+
Le sigue un carácter arroba (@)
A continuación una cadena alfanumérica que incluye el guión (-) y el punto (.), mínimo una vez: [A-Za-z0-9.-]+
Seguido de un punto (.)
Terminando en un cadena alfanumérica con un mínimo de 2 caracteres y máximo 3: ([A-Z|a-z]{2,3})?
Posteriormente hemos realizado una compactación, empleando clases carácter predefinidas, que nos deja la expresión de la forma:
(\w+[\.-]?)+@([\w\.-])+\.([A-Z|a-z]{2,3})?
La descomposición la tenemos en el gráfico siguiente.
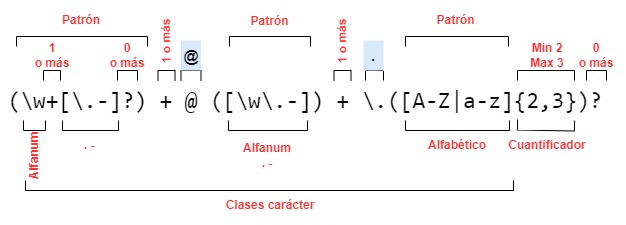
Descomposición de la expresión compacta
El siguiente script nos validará las cadenas de correo electrónico así creadas.
import re
exp = r'([A-Za-z0-9]+[\.-_]?)*[A-Za-z0-9]+@[A-Za-z0-9.-]+\.([A-Za-z]{2,3})?'
email_ok = 'nombre.apellido@host.com'
res = re.fullmatch(exp, email_ok)
if res:
print('email correcto - expresión larga')
print(res)
print(res.group())
# expresión más compacta
expcom = '(\w+[\.-]?)+@([\w\.-])+\.([A-Z|a-z]{2,3})?'
email_ok = 'nombre.ape1-ape2_123@host.sub-xyz.com.es'
res = re.fullmatch(expcom, email_ok)
if res:
print('\nemail correcto - expresión compacta')
print(res.group())
email_nok = 'nombre&apellido@host.com'
res = re.fullmatch(exp, email_nok)
if res:
print(res.group())
else:
print('\nemail erroneo')
email_nok = 'nombre.apellido@host.comcom'
res = re.fullmatch(exp, email_nok)
if res:
print(res.group())
else:
print('\nemail erroneo')
La ejecución del guión nos ofrece el resultado:
email correcto - expresión larga <re.Match object; span=(0, 24), match='nombre.apellido@host.com'> nombre.apellido@host.com email correcto - expresión compacta nombre.ape1-ape2_123@host.sub-xyz.com.es email erróneo email erróneo
Y ahora una expresión Regular que cumple con el RFC 5322, que cubre el 99,99% de las direcciones de correo electrónico, como cortesía de bortzmeyer en stackoverflow: how-can-i-validate-an-email-address-using-a-regular-expression
# compilar con flag=re.VERBOSE
exp = r'''(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\.[a-z0-9!#$%&'*+/=?^_`{|}~-]+)*|
"(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21\x23-\x5b\x5d-\x7f]|
\\[\x01-\x09\x0b\x0c\x0e-\x7f])*")
@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|
\[(?:(?:(2(5[0-5]|[0-4][0-9])|1[0-9][0-9]|
[1-9]?[0-9]))\.){3}(?:(2(5[0-5]|[0-4][0-9])|
1[0-9][0-9]|[1-9]?[0-9])|
[a-z0-9-]*[a-z0-9]:(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21-\x5a\x53-\x7f]|
\\[\x01-\x09\x0b\x0c\x0e-\x7f])+)\])'''
4.3 Búsqueda
En la búsqueda sobre cadenas de texto emplearemos diversas expresiones con diferentes metacaracteres para localizar subcadenas en diferentes zonas del texto. También veremos el uso de diferentes métodos sobre el objeto match que nos devuelve la función search().
import re
# cadena a analizar
cadena = 'En un lugar de la Mancha'
# buscar desde el inicio de la cadena
print('Desde el inicio de la cadena')
res = re.search(r"^En un lugar", cadena)
print(res)
print(f'Cadena localizada:', res.group())
print(f'Posición inicial:', res.start())
print(f'Posición final:', res.end())
print(f'Límites cadena:', res.span())
# buscar antes de la terminación
print('\nAntes de la terminación')
res = re.search(r"la Mancha$", cadena)
print(res)
# buscar en cualquier posición
print('\nEn cualquier posición')
res = re.search(r"lugar", cadena)
print(res)
# buscar en cualquier posición
res = re.search(r"Quijote", cadena)
print(res)
# buscar una o ninguna aparición
print('\nUna o ninguna aparición')
res = re.search(r"nc?", cadena)
print(res)
# buscar cero o más
print('\nCero o más')
res = re.search(r"nc*", cadena)
print(res)
# buscar una o más
print('\nUna o más')
res = re.search(r"nc+", cadena)
print(res)
# buscar una palabra que comienza por mayúscula dentro del texto
print('\nPalabra que comienza por mayúscula en el texto')
res = re.search(r"\s[A-Z]\w*", cadena)
print(res)
En el resultado del guión comprobamos que todas las expresiones regulares nos ofrecen resultado salvo la búsqueda por "Quijote", que no existe en la cadena a analizar.
Desde el inicio de la cadena <re.Match object; span=(0, 11), match='En un lugar'> Cadena localizada: En un lugar Posición inicial: 0 Posición final: 11 Límites cadena: (0, 11) Antes de la terminación <re.Match object; span=(15, 24), match='la Mancha'> En cualquier posición <re.Match object; span=(6, 11), match='lugar'> None Una o ninguna aparición <re.Match object; span=(1, 2), match='n'> Cero o más <re.Match object; span=(1, 2), match='n'> Una o más <re.Match object; span=(20, 22), match='nc'> Palabra que comienza por mayúscula en el texto <re.Match object; span=(17, 24), match=' Mancha'>
4.4 Grupos
En las búsquedas podemos obtener y referenciar subcadenas mediante el uso de grupos, bien con un parámetro numérico o mediante el nombre que le demos al grupo.
Actuaremos sobre una cadena que contiene una fecha y hora, que acompaña a un texto, sacando cada una de sus partes con expresiones regulares que establecen grupos. La fecha-hora sigue el formato ISO 8601, de la forma:
YYYY-MM-DDThh:mm:ss+hh.mm
Emplearemos aquí expresiones regulares muy sencillas, ya que lo que nos interesa es ver la creación y uso de grupos. (Por curiosidad, comparar la expresión que empleamos aquí para la hora con la expresión que utilizamos para la hora en el primer ejemplo).
Para la fecha haremos uso de la expresión:
: (?P<yyyy>[1920]{2}\d\d)-(?P<mm>0[1-9]|1[012])-(?P<dd>0[1-9]|[12][0-9]|3[01])
Para la hora utilizaremos la expresión:
T(?P<hora>[0-1]\d|2[0-3]):(?P<minutos>[0-5]\d):(?P<segundos>[0-5]\d)
Y en el caso de la zona horaria solo atenderemos a la hora, y no pondremos nombre al grupo:
\+([0-1]\d):
Referenciaremos los grupos haciendo uso de todas las posibilidades de que disponemos: por nombre, número o empleando un índice sobre los grupos resultantes.
import re
fecha = "Fecha Madrid ISO-8601: 2022-03-16T11:20:55+01:00"
print('* Fecha')
expr = r': (?P[1920]{2}\d\d)-(?P0[1-9]|1[012])-(?P0[1-9]|[12][0-9]|3[01])'
res = re.search(expr, fecha) #búsqueda
print('objeto match:', res)
print('grupos:', res.groups())
yyyy, mm, dd = res.groups() # desempaquetar la tupla
print('desempaquetado:', yyyy, mm, dd)
print('- por índice de grupos')
print('año:', res.groups()[0])
print('mes:', res.groups()[1])
print('día:', res.groups()[2])
print('- por referencia a grupo')
print('grupo general:', res.group(0))
print('- por nombre / por índice')
print('año:', res.group('yyyy'), '/', res.group(1))
print('mes:', res.group('mm'), '/', res.group(2))
print('día:', res.group('dd'), '/', res.group(3))
print('- posiciones del día')
print('span:', res.span('dd'))
print('start:', res.start('dd'))
print('end:', res.end('dd'))
print('\n* Hora')
expr = r'T(?P[0-1]\d|2[0-3]):(?P[0-5]\d):(?P[0-5]\d)'
res = re.search(expr, fecha) #búsqueda
print('diccionario del grupo:', res.groupdict())
print('- por nombre / por clave')
print('hora: ', res.group('hora'), '/', res.groupdict()['hora'])
print('minutos: ', res.group('minutos'), '/', res.groupdict()['minutos'])
print('segundos:', res.group('segundos'), '/', res.groupdict()['segundos'])
print('\n* Zona horaria')
expr = r'\+([0-1]\d):'
res = re.search(expr, fecha) #búsqueda
print(res.group(1))
El resultado que obtenemos del guión es:
* Fecha objeto match:grupos: ('2022', '03', '16') desempaquetado: 2022 03 16 - por índice de grupos año: 2022 mes: 03 día: 16 - por referencia a grupo grupo general: : 2022-03-16 - por nombre / por índice año: 2022 / 2022 mes: 03 / 03 día: 16 / 16 - posiciones del día span: (31, 33) start: 31 end: 33 * Hora diccionario del grupo: {'hora': '11', 'minutos': '20', 'segundos': '55'} - por nombre / por clave hora: 11 / 11 minutos: 20 / 20 segundos: 55 / 55 * Zona horaria +01
4.5 Búsqueda global
Seguimos con la función de búsqueda, pero en lugar de search() vamos a emplear findall(), que es la función recomendada por Python a partir de la versión 3.
Sobre el siguente fichero del Quijote vamos a buscar, párrafo a párrafo, los diferentes nombres conocidos o supuestos del hidalgo de la Mancha, referenciando el párrafo en el que aprecen.
Emplearemos el fichero quijote.txt para realizar la prueba.
DON QUIJOTE DE LA MANCHA CAPÍTULO PRIMERO Que trata de la condición y ejercicio del famoso hidalgo don Quijote de la Mancha En un lugar de la Mancha, de cuyo nombre no quiero acordarme, no ha mucho tiempo que vivía un hidalgo de los de lanza en astillero, adarga antigua, rocín flaco y galgo corredor. Una olla de algo más vaca que carnero, salpicón las más noches, duelos y quebrantos los sábados, lentejas los viernes, algún palomino de añadidura los domingos, consumían las tres partes de su hacienda. El resto de ella concluían sayo de velarte, calzas de velludo para las fiestas, con sus pantuflos de lo mismo, y los días de entre semana se honraba con su vellorí de lo más fino. Tenía en su casa una ama que pasaba de los cuarenta, y una sobrina que no llegaba a los veinte, y un mozo de campo y plaza, que así ensillaba el rocín como tomaba la podadera. Frisaba la edad de nuestro hidalgo con los cincuenta años. Era de complexión recia, seco de carnes, enjuto de rostro, gran madrugador y amigo de la caza. Quieren decir que tenía el sobrenombre de Quijada, o Quesada, que en esto hay alguna diferencia en los autores que de este caso escriben, aunque por conjeturas verosímiles se deja entender que se llamaba Quejana. Pero esto importa poco a nuestro cuento; basta que en la narración de él no se salga un punto de la verdad.
La expresión regular que emplearemos empieza con la cadena "Qu", seguida de una o más repeticiones de los caracteres [eijs], y un máximo de tres caracteres entre [oteadn]. Hemos llegado a esta expresión revisando los nombres conocidos del Quijote.
Haremos uso del parámetro flags con el valor re.IGNORECASE, para obtener indistintamente mayúsculas y minúsculas.
import re
with open('C:/TestPython/ExpresionesRegulares/quijote.txt', 'r',
encoding='utf-8') as fh:
p = 0
for linea in fh:
p += 1
# buscar los posibles nombres del Quijote en el texto
res = re.findall(r"Qu[eijs]+[oteadn]{3}", linea, flags=re.I)
if res:
print(p, res) # visualizar párrafo y nombres
El resultado del guión nos proporciona los números de párrafos y una lista con las cadenas encontradas en el párrafo:
1 ['QUIJOTE'] 5 ['Quijote'] 8 ['Quijada', 'Quesada', 'Quejana'] 16 ['Quijote', 'Quijada', 'Quesada', 'Quijote'] 17 ['Quijote']
4.6 División
Con las cadenas de caracteres disponemos del método split() para dividir una cadena en una lista de subcadenas. Por defecto divide las cadenas empleando el espacio como carácter delimitador.
El módulo re nos proporciona una función split() que también divide cadenas, pero en lugar de un delimitador hace uso de una expresión regular, lo que nos ofrece una versatilidad mayor.
Vamos a dividir la misma cadena con el método de cadenas, separando por espacios, y con la función con expresión regular separando por caracteres distintos de palabras.
import re
cadena = 'En un lugar de la Mancha, de cuyo nombre no quiero acordarme'
print('* División con split')
print(cadena.split())
print('\n* División con split con expresión regular')
print(re.split(r'\W+', cadena))
En el resultado vemos, en el primer caso, que al dividir empleando el espacio nos aparece una coma acompañando a la palabra 'Mancha'.
En el segundo caso, empleamos como separador cadenas de uno o más caracteres que no son palabras, ya no aparece la coma después de la palabra 'Mancha'.
* División con split ['En', 'un', 'lugar', 'de', 'la', 'Mancha,', 'de', 'cuyo', 'nombre', 'no', 'quiero', 'acordarme'] * División con split con expresión regular ['En', 'un', 'lugar', 'de', 'la', 'Mancha', 'de', 'cuyo', 'nombre', 'no', 'quiero', 'acordarme']
4.7 Reemplazamiento
En la función de reemplazamiento el primer parámetro es una expresión regular que selecciona las suabcadenas que vamos a reemplazar con el segundo parámetro, que puede ser una cadena, una expresión regular e incluso una función. El tercer parámetro es la cadena sobre la vamos a actuar.
(1) En el primer ejemplo la expresión hace referencia a los espacios al principio de la cadena o al final. El resultado lo reemplazamos por la cadena vacía.
(2) En el segundo ejemplo aplicamos al tercer parámetro la función anterior y tomando la cadena resultante reemplazaremos cualquier número de espacios por un único espacio. Eliminando así todos los espacios duplicados.
(3) En el tercer ejemplo tenemos una fecha en formato americano (mm/dd/yyyy) y la reemplazaremos por la fecha en formato ISO (yyyy-mm-dd). Haremos uso de grupos que referenciaremos por número en la cadena de sustitución.
(4)(5) En los dos siguientes ejemplos crearemos y emplearemos funciones para cambiar la caja de los caracteres del texto, todo a minúsculas y mayúsculas por minúsculas y viceversa.
(6) En el último ejemplo emplearemos la función subn(), que además de realizar los cambios nos informa del número de cambios que ha realizado.
import re
# (1) eliminar espacios al principio y final
s = ' En un lugar de la Mancha '
res = re.sub(r'^\s+|\s+$', '', s)
print('(1) eliminar espacios al principio y final')
print(f'Con espacios en los extremos: >{s}<')
print(f'Sin espacios en los extremos: >{res}<')
# (2) eliminar espacios al principio y final
# y reducir múltiples espacios a un solo espacio
res = re.sub(r'\s+', ' ', re.sub(r'^\s+|\s+$', '', s))
print('\n(2) eliminar múltiples espacios')
print(f'Sin espacios en extremos ni interiores: >{res}<')
# (3) fecha formato americano (mm/dd/yyyy)
# pasar a formato ISO
s = 'Fecha 03/17/2022'
res = re.sub(r'(\d{1,2})/(\d{1,2})/(\d{4})', r'\3-\1-\2', s)
print('\n(3) Pasar a formato ISO')
print(f'Fecha formato americano: {s}')
print(f'Fecha ISO: {res}')
s = 'ESto ES un TExtO EscRIto POr uN LocO'
# (4) función para pasar todo a minúsculas
def to_lower(obj):
if obj.group() is not None:
return obj.group().lower()
res = re.sub(r'[A-Z]', to_lower, s)
print('\n(4) Uso de función para pasar todo a minúsculas')
print(f'Texto: {s}')
print(f'Todo minúsculas: {res}')
# (5) función para cambiar caja
# mayúsculas a minusculas y viceversa
def change_case(obj):
if obj.group(1) is not None:
return obj.group(1).lower()
elif obj.group(2) is not None:
return obj.group(2).upper()
res = re.sub(r'([A-Z])|([a-z])', change_case, s)
print('\n(5) Uso de función para cambiar de caja')
print(f'Cambio de caja: {res}')
# (6) cambiar caja y contar cambios
res = re.subn(r'([A-Z])|([a-z])', change_case, s)
print('\n(6) Cambio de caja y contador')
texto, cuenta = res # desempaquetar la respuesta
print(f'Cambio de caja: {texto}')
print(f'Cambios realizados: {cuenta}')
La ejecución del guión nos ofrece el resultado:
(1) eliminar espacios al principio y final Con espacios en los extremos: > En un lugar de la Mancha < Sin espacios en los extremos: >En un lugar de la Mancha< (2) eliminar múltiples espacios Sin espacios en extremos ni interiores: >En un lugar de la Mancha< (3) Pasar a formato ISO Fecha formato americano: Fecha 03/17/2022 Fecha ISO: Fecha 2022-03-17 (4) Uso de función para pasar todo a minúsculas Texto: ESto ES un TExtO EscRIto POr uN LocO Todo minúsculas: esto es un texto escrito por un loco (5) Uso de función para cambiar de caja Cambio de caja: esTO es UN teXTo eSCriTO poR Un lOCo (6) Cambio de caja y contador Cambio de caja: esTO es UN teXTo eSCriTO poR Un lOCo Cambios realizados: 29
4.8 Iterador
La función finditer() además de buscar un patrón en una cadena devuelve un iterador con los objetos localizados.
En el siguiente ejemplo vamos a localizar las vocales que aparecen en un texto, y con el iterador recorreremos e resultado para crear un diccionario contando las ocurrencias de cada vocal.
La expresión regular contiene un conjunto con las cinco vocales. En la función haremos uso del parámetro flags con re.IGNORECASE, para que las coincidencias en la búsqueda sean insensibles a las mayúsculas y minúsculas.
import re
s = 'En un lugar de la Mancha, de cuyo nombre no quiero acordarme'
exp = '[aeiou]'
res = re.finditer(exp, s, flags=re.IGNORECASE) # independiente de la caja
vocales = {}
for x in res:
# pasar vocales a minúsculas
vocal = x.group().lower()
# contar en el diccionario
vocales[vocal] = vocales.get(vocal, 0) + 1
print(dict(sorted(vocales.items())))
El resultado del guión es:
{'a': 6, 'e': 6, 'i': 1, 'o': 5, 'u': 4}
4.9 Compilador
Si se va a utilizar la misma expresión regular más de una vez en un guión, y, sobre todo, si es una expresión grande, es mejor compilar la expresión y utilizar el objeto resultante.
La compilación ahorra tiempo, pero no mucho, ya que Python compila internamente las expresiones que usamos y las almacena para un uso posterior. El único tiempo que ahorramos es el que necesita Python para comprobar la caché y localizar la compilación.
Vamos a emplear la expresión regular que obtuvimos en stackoverflow: how-can-i-validate-an-email-address-using-a-regular-expression, que comentamos en el ejemplo de validación de una dirección de email.
Hemos sacado de la Wikipedia: Email_address direcciones de correo válidas y erróneas. Procederemos a validarlas compilando inicialmente la expresión.
import re
# direcciones obtenidas en https://en.wikipedia.org/wiki/Email_address
# direcciones correctas
email_ok = '''user.name+tag+sorting@example.com
x@example.com
mailhost!username@example.org
postmaster@[123.123.123.123]
"john..doe"@example.org'''
# direcciones erroneas
email_nok = '''Abc.example.com
i_like_underscore@but_its_not_allowed_in_this_part.example.com
QA[icon]CHOCOLATE[icon]@test.com
just"not"right@example.com'''
# expresión para validar email
exp = r'''(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\.[a-z0-9!#$%&'*+/=?^_`{|}~-]+)*|
"(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21\x23-\x5b\x5d-\x7f]|
\\[\x01-\x09\x0b\x0c\x0e-\x7f])*")
@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|
\[(?:(?:(2(5[0-5]|[0-4][0-9])|1[0-9][0-9]|
[1-9]?[0-9]))\.){3}(?:(2(5[0-5]|[0-4][0-9])|
1[0-9][0-9]|[1-9]?[0-9])|
[a-z0-9-]*[a-z0-9]:(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21-\x5a\x53-\x7f]|
\\[\x01-\x09\x0b\x0c\x0e-\x7f])+)\])'''
# compilar la expresión regular
exp_comp = re.compile(exp, flags=re.VERBOSE)
print('* email correctos obtenidos en la Wikipedia')
for email in email_ok.split('\n'):
print(email)
res = exp_comp.search(email)
print(res)
print('\n* email erroneos obtenidos en la Wikipedia')
for email in email_nok.split('\n'):
print(email)
res = exp_comp.search(email)
print(res)
La ejecución del guión, con los grupos de direcciones y la expresión regular compilada, nos ofrece algún resultado inesperado.
* email correctos obtenidos en la Wikipedia user.name+tag+sorting@example.com <re.Match object; span=(0, 33), match='user.name+tag+sorting@example.com'> x@example.com <re.Match object; span=(0, 13), match='x@example.com'> mailhost!username@example.org <re.Match object; span=(0, 29), match='mailhost!username@example.org'> postmaster@[123.123.123.123] <re.Match object; span=(0, 28), match='postmaster@[123.123.123.123]'> "john..doe"@example.org None * email erroneos obtenidos en la Wikipedia Abc.example.com None i_like_underscore@but_its_not_allowed_in_this_part.example.com None QA[icon]CHOCOLATE[icon]@test.com None just"not"right@example.com <re.Match object; span=(9, 26), match='right@example.com'>
Vemos que en el grupo de direcciones que se suponen correctas hay una que no es reconocida por la expresión regular: "john..doe"@example.org
Otro tanto ocurre entre las direcciones que se suponen erróneas, que no todas lo son bajo la lupa de la expresión regular que empleamos: just"not"right@example.com
Como comentábamos al principio de la sección, la construcción de una expresión regular no es algo trivial, sobre todo cuando lo que pretendemos analizar tiene un grado de complejidad alto.